Адрес для входа в РФ: toffler.lol
Что искусственный интеллект-то вытворяет! Мало того, что озвучивает на других языках, но при этом еще и сохраняет оригинальные голоса актёров, фантастика!
Проверял тут одну штуку. Попросил четыре разных ИИ нарисовать группу довольных мужчин, безо всяких уточнений.
Stable Diffusion, реалистичная модель.

DALL-E в ChatGPT.

Плагин Image Edit and img2img в ChatGPT.

DALL-E в CoPylot. Единственный, кто добавил атмосферу праздника.

Ну и вот статья со сравнением результатов рисования по разным промптам четырех AI: Stable Diffusion, Midjourney, DALL-E vivid и DALL-E natural.

OpenAI представила модель GPT-4o, которая умеет полноценно общаться человеческим голосом: интонации, смех, запинки и так далее.
Вот демонстрация. Впечатляет, да.
Upd: И еще одна демонстрация - эта модель используется для перевода с английского на испанский и обратно.

Компания Microsoft представила модель искусственного интеллекта VASA-1, предназначенную для генерирования реалистичных видео персонажей, произносящих заданный текст, по одной фотографии и аудиоклипу с речью. VASA-1, способна не только воспроизводить движения губ, синхронизированные со звуком, но и улавливать широкий спектр нюансов лица и естественных движений головы, которые способствуют реалистичному восприятию.
Пишут, что эта модель поддерживает онлайн-генерацию видео 512x512 с частотой до 40 кадров в секунду с незначительной задержкой.
Для чего это может применяться? Ну, например, для создания реалистичных аватаров, которые имитируют человеческий разговор.
На странице проекта выложено множество примеров работы VASA-1, вот один из них.
Ну и вот ролик, который показывает, как работает эта технология в реальном времени.
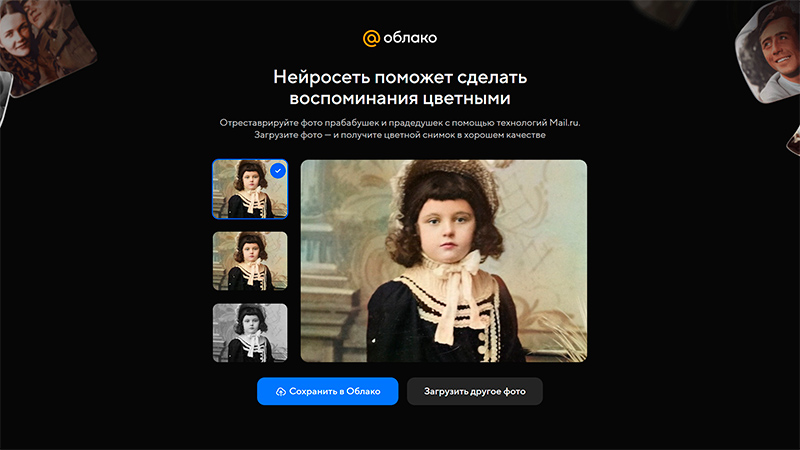
Попалась тут ссылка на нейросеть для реставрации и раскрашивания старых фото. Работает в онлайне, бесплатная.
Погонял на всяких произвольных старых фото. Ну, в принципе, работает вполне неплохо. Никак не идеально, но неплохо. А до нужного вида потом можно в "Фотошопе" довести.




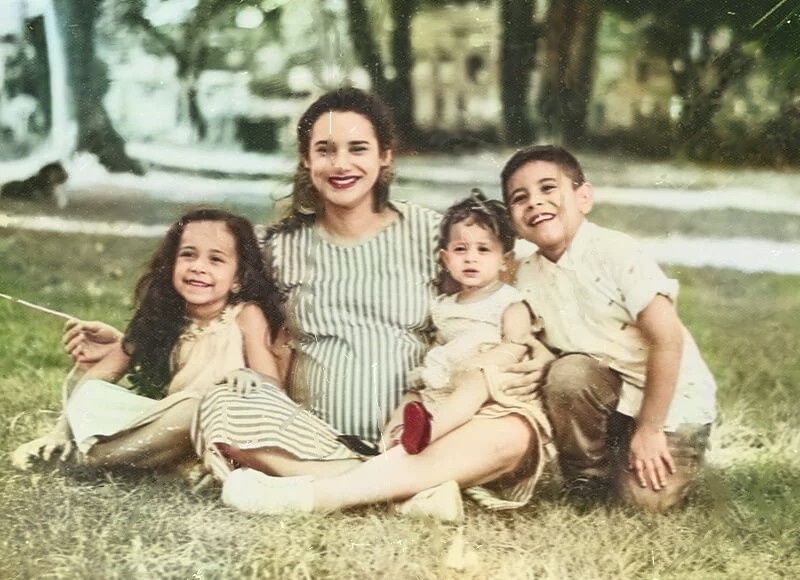
Следы невиданных зверей!
Don Allen Stevenson III в содружестве с OpenAI и моделью Sora создал демонстрационный ролик о несуществующих животных.
Вот что он пишет в описании (оригинал на английском).
Я очень рад представить нечто поистине революционное в сотрудничестве с @openai - взгляд в будущее повествования с помощью технологии Sora. 🌟
В этом трейлере мы исследуем параллельный мир за пределами нашей реальности, где границы воображения расширяются, оживляя несколько существ, которых я придумал. То, что вы видите, - это не традиционные кадры 🎞️, а результат работы новейшей видеотехнологии, созданной искусственным интеллектом, которая стирает границы между реальностью и фантазией. Я попытался заложить в основу своих работ что-то знакомое, например, животных, но также и то, что в настоящее время невозможно с точки зрения биологии, 🧬 эти гибридные существа.
Сейчас, когда мы вступаем в новую эру, я понимаю опасения, связанные с быстрой эволюцией наших творческих индустрий. Я действительно считаю, что Sora предлагает другой вид визуального холста, расширяя мои творческие возможности и дополняя мои различные творческие ремесла. Я всегда был творческой студией, состоящей из одного человека, поэтому существовали ограничения на то, что я мог создать в одиночку. С Sora я чувствую, что могу рассказывать истории в таких масштабах, которые раньше мне казались невозможными.
Продолжая быть ранним художником, работающим с Sora, я обещаю помнить о ее глубоком влиянии. Я буду продолжать делиться знаниями о ней в образовательном и творческом качестве.
Я чувствую, что мы открываем 🔓 новую эру творческого повествования, которую мы никогда раньше не могли представить коллективно! Оставайтесь любопытными и творческими!!!
Ну и вот сам ролик, который некоторым образом взрывает мозг...

Компания HarrisX, занимающаяся различными маркетинговыми исследованиями, по заказу Variety Intelligence Platform (VIP+) провела исследование на тему того, могут ли люди отличить видео, созданное инструментом "текст в видео" Sora от OpenAI от реальных видеороликов.
Вот подробные результаты исследования.
Кратко. Более чем 1000 участников в режиме онлайн показывали четыре реалистичных видео, созданных Sora, и четыре видео с похожими сюжетами из стокового материала. В итоге в 60% испытуемые считали, что ролики от Sora - созданы человеком.
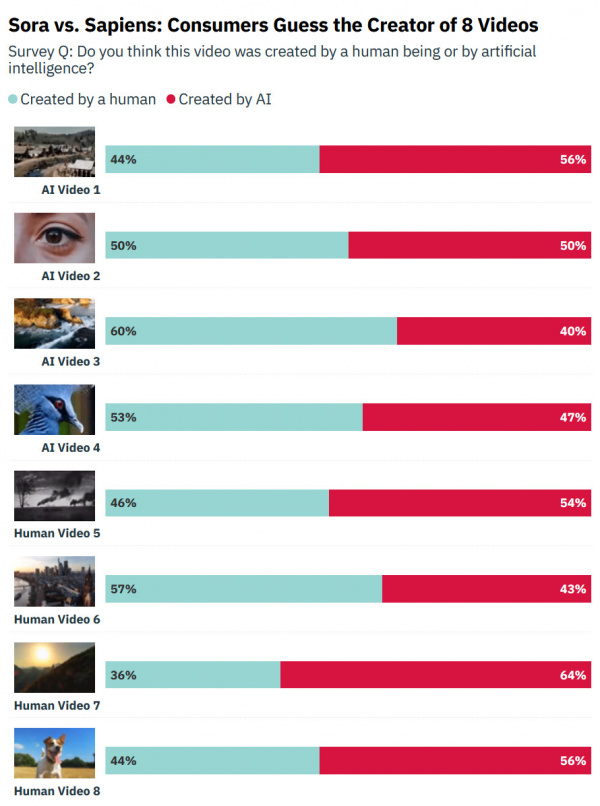
После этого респондентам сообщили, какие именно ролики созданы Sora, которые они приняли за реальные, и спросили, что они в связи с этим чувствуют. Реакция была смешанной, положительной и отрицательной: от любопытства (28 %), неуверенности (27 %) и непредвзятости (25 %) до тревоги (18 %), вдохновения (18 %) и страха (2 %).
Также на вопрос, считают ли респонденты, что правительство США должно принять постановление, требующее, чтобы контент, созданный искусственным интеллектом, был обозначен как таковой - респонденты одинаково категорично заявили о необходимости регулирования всех форматов контента, включая видео, изображения, текст, музыку, субтитры и звуки.
 Image credit: Adobe Stock/ _veiksme_
Image credit: Adobe Stock/ _veiksme_
Компания Adobe представила проект Music GenAI - это ресурс на основе искусственного интеллекта для создания и настройки музыкальных произведений из текстовых подсказок. Система была разработана в сотрудничестве с Калифорнийским университетом и Школой компьютерных наук Университета Карнеги-Меллон.
В издании Wired пишут, что данная система является частью платформы Firefly, семейства моделей искусственного интеллекта, которые были интегрированы в такие сервисы, как Photoshop, Illustrator и Express. Она работает аналогично моделям MusicLM от Google и AudioCraft от Meta. Достаточно ввести запрос, описывающий тип и стиль желаемой мелодии, после чего ИИ выдаст песню с заранее заданными характеристиками. Модель также способна генерировать результаты на основе уже существующей эталонной композиции.
В отличие от других подобных программ, этот подход включает в себя встроенные элементы управления редактированием. Проект позволяет легко вносить изменения в структуру, темп, интенсивность и повторяющиеся паттерны генерируемого произведения. Она позволяет смешивать фрагменты разных клипов, создавать музыкальные петли и увеличивать продолжительность произведений.
Впрочем, пока проект находится на ранней стадии разработки, и пока нет никаких подробностей о том, как будет работать интерфейс, как будет обеспечиваться безопасность исходных материалов и какова максимальная длина клипов, которые можно будет создавать.
Ну и вот небольшая демонстрация возможностей этой модели, которую показала компания Adobe.
Совсем недавно компания OpenAI представила модель ИИ под названием Sora, которая умеет создавать реалистичные видео по обычным текстовым запросам.
А теперь компания ElevenLabs, занимающаяся автоматической озвучкой текста и генерацией аудио, показала, как ее ИИ может создавать озвучку для видео - тоже по простым текстовым промптам.
В демонстрационном ролике озвучиваются примеры, созданные Sora.
Кстати, компания ElevenLabs была основана Петром Дабковским, бывшим инженером по машинному обучению Google, и Мати Станишевским, бывшим стратегом по внедрению Palantir, для разработки сверхреалистичных моделей преобразования текста в речь для образования, аудиокниг, игр, фильмов, бизнеса и так далее. Компания получила $19 млн инвестиций.
И вот один из впечатляющих примеров их разработок: ИИ вслух читает роман Скотта Фицджеральда "Великий Гэтсби".
ИИ открывает новые горизонты. Компания OpenAI продемонстрировала новую модель ИИ под названием Sora. Эта модель умеет создавать реалистичные и впечатляющие видео по обычным текстовым запросам. Вот подробное описание того, на чем строится данная технология.
Приведенные примеры впечатляют безмерно. И там утверждается, что это именно результаты приведенных запросов без дополнительной обработки.
А ведь еще с год назад ИИ по текстовым описаниям рисовала разве что кривенькие картинки. А уж когда ИИ пытался нарисовать видео по запросу - получалось то самое видео с Уиллом Смитом, над которым ржал весь Интернет (я его в P.S. привел).
Вот, например, запрос (перевод с английского):
Стильная женщина идет по токийской улице, залитой теплым светящимся неоном и анимированными городскими вывесками. На ней черная кожаная куртка, длинное красное платье, черные сапоги и черная сумочка. На ней солнцезащитные очки и красная помада. Она идет уверенно и непринужденно. Улица влажная и отражающая, что создает зеркальный эффект разноцветных огней. На улице много пешеходов.
Кошка будит свою спящую хозяйку, требуя завтрак. Хозяйка пытается игнорировать кота, но тот пробует новые тактики, и в конце концов хозяйка достает из-под подушки тайник с лакомствами, чтобы отвлечь кота.
Тут, кстати, с лакомством что-то не сложилось, но кот - это что-то с чем-то!
В анимированной сцене крупным планом изображен короткий пушистый монстр, стоящий на коленях возле тающей красной свечи. Художественный стиль - 3D и реалистичный, с акцентом на освещение и текстуру. Настроение картины - удивление и любопытство, ведь монстрик смотрит на пламя широко раскрытыми глазами и открытым ртом. Его поза и выражение лица передают ощущение невинности и игривости, как будто он впервые исследует окружающий мир. Использование теплых цветов и эффектного освещения еще больше усиливает уютную атмосферу изображения.




